-
AWS Lambda 에서 NumPy, Pandas 쓰는 법DSC 프로젝트/챗봇 만들기 2020. 2. 24. 19:58728x90반응형
내가 활동하고 있는 DSC 동아리에서 챗봇 프로젝트를 진행하기로 했다.
프로젝트 주제는 유저에게 맞춤 비타민을 추천해주는 것. 증상이나 고민을 물어보고, 필요한 비타민 종류를 말해줄 뿐만 아니라, 성별/나이대등을 받아서 그에 맞는 비타민도 추천해 주는 비타민 추천 챗봇이다.
사용한 기술 스택은 Python3.7, AWS Lambda, AWS API Gateway, 카카오 i 오픈빌더.
카카오 i 오픈빌더, AWS Lambda, API Gateway 를 활용하면 카카오톡 채널에 serverless 챗봇을 쉽게 만들 수 있다.
우리는 비타민 종류와 그 해당 비타민이 결핍시 생기는 증상을 csv 파일로 정리한 후,
pandas로 csv 파일을 읽어서 사용자가 말한 증상을 입력하면, 필요한 비타민의 종류들을 출력해주기로 했다.
하지만 AWS Lambda 에서는 pandas 를 기본적으로 지원하지 않는 것.
람다 함수에서 pandas를 임포트하면 크기가 너무 커 임포트할 수 없다고 나온다.
구글을 뒤적여 아래의 글을 보고 람다에서 pandas 를 사용하는 방법을 알아냈다.
*참고사이트 : https://medium.com/@korniichuk/lambda-with-pandas-fd81aa2ff25e
AWS Lambda with Pandas and NumPy
AWS Lambda does not include Pandas/NumPy Python libraries by default. How use Pandas and NumPy with Lambda functions?
medium.com
한국어로 된 블로그글이 마땅치 않은 것 같아서... 위 글을 참고해 AWS 람다에서 python pandas 라이브러리를 쓰는법, 그리고 카카오 아이 오픈빌더에 연결해 챗봇에 결과가 출력되게 하는 방법까지 소개해 보려고 한다.
카카오톡 채널에 챗봇 생성
만들고 싶은 채널을 하나 만들고, 카카오 아이 오픈빌더에 OBT 권한 신청을 하면, 2~3일이 소요된다.
권한이 인정되면, 이렇게 나의 봇에 챗봇이 하나 보일것이다. 기본적인 준비는 이것으로 끝이다.

AWS Lambda 함수 생성
그 다음, AWS Lambda함수를 생성해준다.


함수 이름과 런타임을 적는다. 나같은 경우에는 python3.7 을 넣었다. 그리고 함수 생성 버튼을 누른다.
AWS Lambda 에서 Pandas 쓰기
그 다음 문제는, AWS Lambda에 pandas 를 그냥 쓸 수가 없다.
AWS Lambda 실행 환경과 사용 가능한 라이브러리는 여기서 확인 가능하다.
우선 pandas 가 잘 임포트 되는지 테스트할 파이썬 코드는 다음과 같다.
import pandas as pd def lambda_handler(event, context): passAWS 람다에서 그냥 테스트해보면,
Unable to import module 'lambda_function': No module named 'pandas'라고 나올거다.
새로운 디렉토리를 하나 만들고, 그 안에 lambda_function.py 파일을 생성하고 위의 파이썬 코드를 작성하고 저장한다.
그리고 pip 을 이용해 pandas 를 로컬 디렉토리에 설치한다.
$ pip install -t . pandas*.dist-info 와 __pycache__ 를 제거한다. 그리고 이 디렉토리를 zip.zip 으로 압축한다.
$ rm -r *.dist-info __pycache__ $ zip -r zip.zip .그러면 디렉토리는 다음과 같은 파일들이 있을것이다.
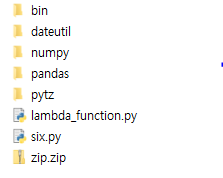
압축한 파일을 AWS Lambda 함수 코드에 넣어준다. AWS Lambda 의 함수 코드 쪽에 가서,
Code entry type 을 .zip 파일 업로드를 선택하고, Runtime 에 Python 3.7로 설정하고,
함수 패키지에 업로드 버튼을 눌러 zip.zip 파일을 업로드 해준다. 그리고 Save 버튼을 눌러 저장하는걸 잊지 말자.

그리고 Save 버튼 옆 테스트 버튼을 눌러 결과를 확인한다. 응답은 다음과 같을 것이다.
Unable to import module 'lambda_function': Missing required dependencies ['numpy']엥? numpy 가 빠졌다고? pandas 라이브러리는 numpy 를 포함하고 있다. 아까 압축했던 디렉토리를 보면, numpy 도 설치되었던 것을 확인할 수 있다.

흠... AWS Lambda는 특별한 pandas/numpy 가 필요하다..
다시 고쳐보자.우선 이 디렉토리에 pandas, numpy, *.dist-info 파일을 제거한다.
AWS Lambda 는 Amazon Linux 운영체제를 사용하기 때문에,
Amazon Linux 와 호환되는 pandas 와 numpy 를 다운로드 해준다.
Pandas는 https://pypi.org/project/pandas/#files로 가서 *manylinux1_x86_64.whl 패키지 중 자신이 설정한 python 버전에 맞는 것을 다운로드 해준다.
나의 경우는 python 3.7 버전을 사용하기 때문에 pandas-1.0.1-cp37-cp37m-manylinux1_x86_64.whl
을 다운받아 주었다.
Numpy 로 같은 방법으로 다운로드 해준다. https://pypi.org/project/numpy/#files로 가서 numpy-1.18.1-cp37-cp37m-manylinux1_x86_64.whl 를 다운받아준다.
whl 파일들을 아까 만든 lambda_function.py 가 있는 디렉토리에 다운받아 주었으면 다음 명령어를 입력해 Unzip 해준다.
$ unzip numpy-1.18.1-cp37-cp37m-manylinux1_x86_64.whl $ unzip pandas-1.0.1-cp37-cp37m-manylinux1_x86_64.whl그리고 다음 명령어도 실행해준다.
$ pip install -t . pytz그리고 *.dist-info, __pycache__ 를 제거하고, 마찬가지로 이 디렉토리 안에 있는 파일들을 zip 파일로 압축한다.
$ rm -r *.whl *.dist-info __pycache__ $ zip -r zip.zip .그리고 다시 AWS Lambda 로 가서 zip 파일을 함수 코드에 업로드 해준다.
테스트해보면 성공했다는 로그가 뜰 것이다.
자! 그럼, 우리가 pandas 를 이용해 원하는 수행을 하는 코드를 넣어 AWS Lambda에서 실행할 수 있다.
이 글에서는 카카오 아이 오픈빌더에서 만든 챗봇에 AWS Lambda를 연결하는 거니, 계속 해보겠다.
AWS Lambda 를 API Gateway 를 이용해 카카오톡 챗봇에 연결
API URL 을 만들어 배포해야 하기 때문에, API Gateway를 사용해주겠다.
AWS Lambda 페이지 상단에 트리거 추가 버튼을 누른다.

트리거 구성에서 API 게이트웨이 설정. 기존 API 가 있으면 그것을 설정해주고, 아니면 새 API 생성을 선택한다.

새 API 생성할때, REST API 를 선택하고, 보안은 API 키로 열기를 하는 것을 추천한다. 그래야 보안이 좋다..
그러나 카카오 오픈빌더에서 API 키를 헤더로 넘겨줬을때 도저히 출력히 제대로 나오지 않아.. 나는 결국 API 키를 없는 것( = 열기) 으로 선택했다. 아마도 오픈빌더가 아직 베타버전이라 오류가 있는것 같기도..

그리고 API 게이트웨이에 들어가보면 이미 ANY 리소스가 생성되어있을 것이다. 이는 GET, POST 등 모든 HTTP 리퀘스트를 받을 수 있다는 의미다. 작업에서 API 배포를 누른다.

만약 API 키로 열기로 설정했다면, 메소드 요청에 들어가 API 키가 필요함에서 false 를 true 로 바꾸고, API 키를 설정해준다.

오픈빌더를 위해 Lambda 함수코드 수정하기
오픈빌더를 사용할 때, 람다 함수 작성에서 유의해야할점은, 입력으로 받아오는 json 형식과 출력 json 형식이 정해져 있기 때문에 함수 코드를 이에 맞게 짜 주어야 한다.
import pandas as pd import json import ctypes def lambda_handler(event, context): request_body = json.loads(event['body']) params = request_body['action']['params'] # 오픈빌더는 action > params 안에 input 데이터가 들어있다. test = params['symptom'] # action > params 안에 symptom 파라미터의 값을 가져와 test 에 넣는다. ... # input 으로 받아온 데이터로 원하는 결과를 생성하는 코드 작성 result = { "version": "2.0", "data":{ "test": test, } } return { 'statusCode':200, 'body': json.dumps(result), 'headers': { 'Access-Control-Allow-Origin': '*', } }기본적인 형태는 다음과 같다. 오픈빌더는 POST 로만 http 요청을 받는다.
또한 result 에 설정해 줄 수 있는 값들이 있는데 version 은 꼭 2.0으로 명시해 주지 않으면 구 버전으로 오픈빌더가 실행된다. 그리고 data 안에 출력데이터를 작성한다.
더 자세한 것은 오픈빌더 가이드북에 설명되어 있으니 참고하길 바란다.
AWS Lambda 함수를 스킬로 등록하기
배포한 API를 스킬로 등록해보자. 스킬 작성에 대한 내용은 여기에 잘 나와있으니, 이 글에선 자세한 내용을 생략하겠다.
스킬 메뉴에서 스킬을 생성하고, 아까 배포한 API URL 을 입력해준다. 만약 API 키를 설정하였으면, 헤더값에
x-api-key 를 추가하고 값으로 API 키 값을 넣어준다.

요청할 파라미터 값을 입력해준다. 옆에 json 형식으로 요청을 볼 수 있다. 이것으로 자신이 입력한 값이 잘 전달되고 있는지 확인하자.

action 안에 params 안에 symptom 파라미터 안에 값이 잘 전달되엇다.
{ "intent": { "id": "vx5bcjj48zgfghsofdomu50h", "name": "블록 이름" }, "userRequest": { "timezone": "Asia/Seoul", "params": { "ignoreMe": "true" }, "block": { "id": "vx5bcjj48zgfghsofdomu50h", "name": "블록 이름" }, "utterance": "발화 내용", "lang": null, "user": { "id": "135710", "type": "accountId", "properties": {} } }, "bot": { "id": "5e50c9488192ac0001584540", "name": "봇 이름" }, "action": { "name": "9na3iy70yi", "clientExtra": null, "params": { "symptom": "탈모" }, "id": "69a6hwsfkq0em5s8qdbutgik", "detailParams": { "symptom": { "origin": "탈모", "value": "탈모", "groupName": "" } } } }시나리오에서 블록을 생성하고, 결과값이 잘 출력되는지 확인
get_symptom 이라는 블록을 하나 만들고, 사용자 발화에 예상되는 발화들을 몇개 넣어주었다. 20개 이상 입력하면 머신러닝을 사용할 수 있다. 내가 받을 사용자 발화는 증상에 대한 내용이므로, 증상에 해당되는 단어를 엔티티로 태깅했다.

엔티티는 상단에 엔티티 메뉴에서 추가할 수 있다. 엔티티는 다른 말로 단어 사전쯤 된다. 사용자 발화에 의도한 키워드를 엔티티로 태깅해 놓으면, 오픈빌더가 알아서 엔티티에 해당되는 내용이 있으면, 그에 맞는 답변을 생성하고, 없으면 되묻기를 통해 사용자의 의도를 다시 찾는다. (필수 파라미터로 설정하지 않았다면 되묻기 하지 않을 수 있음.)

커스텀 엔티티는 내가 직접 만든 엔티티를 말하고, 시스템 엔티티도 여러가지 제공하고 있다. 날짜나 물건 단위, 숫자 등이 해당된다.
파라미터를 설정해주고, 스킬을 등록해준다.
봇 응답에서 result 로 넘겨준 값들을 {{#webhook.<json_path>}}의 표현으로 설정해준다.
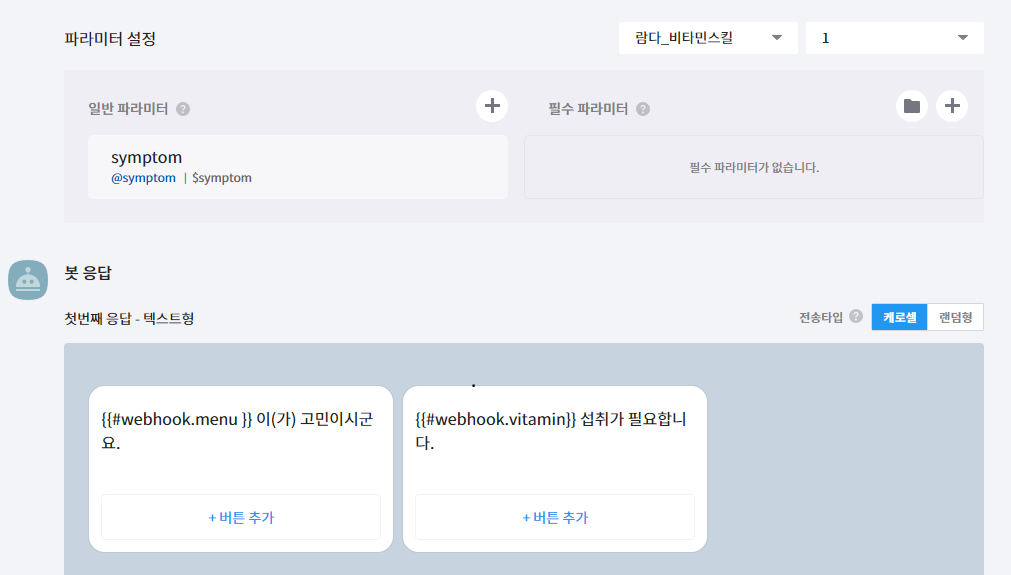
나같은 경우에 스킬 호출결과가 다음과 같으므로, 텍스트형 말풍선에 위와 같이 넣어줬다.
{ "version": "2.0", "data":{ "menu": ans, "vitamin": vitamin } }저장 후, 테스트 해봤더니 잘 나오는 것을 볼 수 있다.

*이 글에서 사용한 코드 풀 버전은 제 github에 올라와 있으니, 참고해서 연습해보고 싶으신 분들께 도움이 되셨으면 좋겠습니다:)
https://github.com/jennkimm/VitaminBot
GitHub - jennkimm/VitaminBot: 카카오톡 플러스친구 비타민추천 챗봇만들기 프로젝트
카카오톡 플러스친구 비타민추천 챗봇만들기 프로젝트. Contribute to jennkimm/VitaminBot development by creating an account on GitHub.
github.com
728x90'DSC 프로젝트 > 챗봇 만들기' 카테고리의 다른 글
장고 프로젝트 배포하기 (pythonanywhere 과 AWS EC2) (3) 2020.03.10